Introducing Async Service
Distributed tasks with Postgres & Rabbitmq
TL;DR: Check out the code here
At my workplace, we needed a mechanism to:
- Have service A tell service B to start executing long-running tasks, with notifications upon completion
- Add reliability to cross-service infrastructure to be resilient to temporary outages
- Support nested jobs where Job 1 needs to complete sub-steps 1a, 1b, 1c, etc. which are all jobs themselves
- Support scaling to accommodate large surges of jobs
I considered different off-the-shelf products, but ended up feeling like we would need to fork the functionality to get the behavior we wanted. I also wanted to avoid introducing yet-another-stack, query syntax, and more into our system. Since our backend already is based around postgres and rabbitmq, I singlehandedly designed and implemented async service to handle our needs.
Architecture diagram
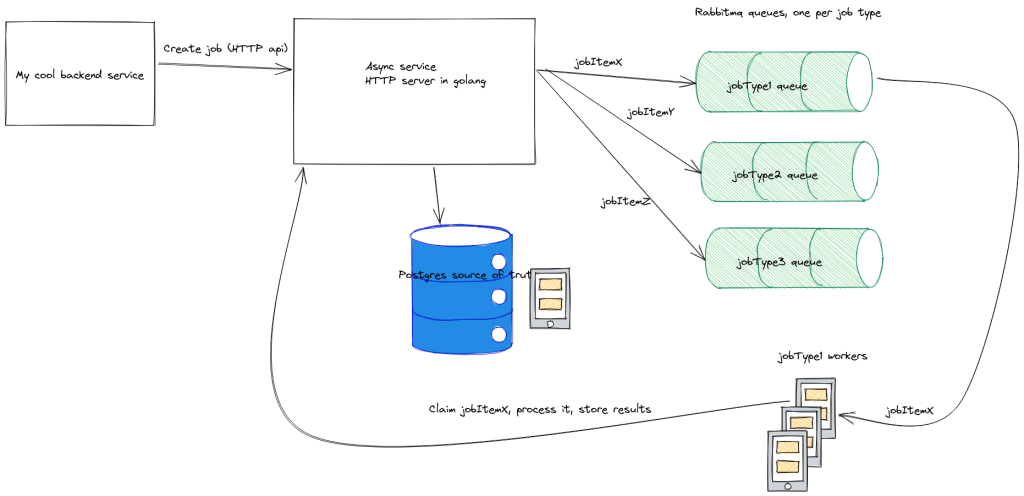
At its core, async service is a HTTP server which has REST endpoints for creating jobs, managing jobs etc. It uses postgres as the source of truth for all of the data. Then, to handle worker discovery, fanout, and queue management, async service sends out jobItemIds to rabbitmq. Workers listen to the queue and then use HTTP api’s on async service to claim the job. From that point on, the worker can process the job for as long as it wants, as long as it periodically sends back “I’m alive heartbeats” to async service. Finally, the worker returns success or failure via an HTTP call to async service, where it is stored in postgres
Important design considerations
- Postgres is the singular source of truth. Items in rabbitmq can be duplicates, not complete etc, and that’s ok
- Async service is an ephemeral store. Jobs are only stored in postgres for a limited time. It’s up to services to pull the results out and store them elsewhere before the table is reaped
- The logic inside async service is meant to be as simple and straightforward as possible. Correctness guarantees are made entirely by the postgres layer.
- The service’s job is just to read/write to postgres, and then handle side effects – e.g. when a jobItem is created, put the jobItemId onto rabbit
- A job’s taxonomy is known at creation time – e.g. this job takes these 5 steps to complete. However, the actual data for each step can optionally stream in as the job progresses
Postgres data model
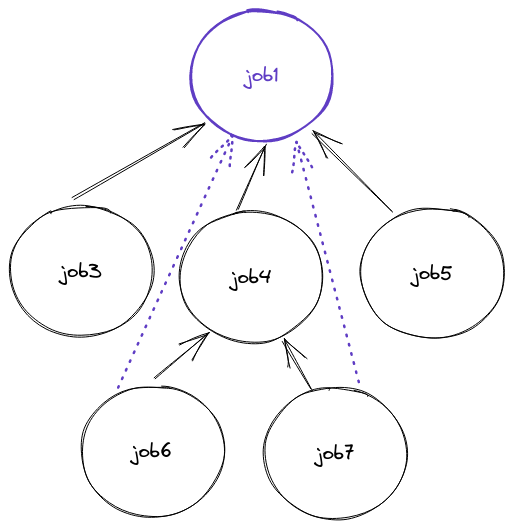
Jobs
Jobs are modeled as a tree structure. All jobs have a root job, and may contain child jobs that are dependent on the root job in some way. As in a typical tree structure, all jobs (besides the root) have a reference to their parent job. Additionally, since the root job is very important (and also recursion is not easy in postgres queries), each job also stores a reference to the root_job. In the image below, each black arrow corresponds to a parent_job_id, and the purple arrows are root_job_ids
JobItems
A job doesn’t contain any data itself. Instead, a job is a container for jobItems. A jobItem is the fundamental unit of work within async service. It describes some input (the payload) that needs to get processed, as well as the result or failures from the worker post-processing.
Jobs contain zero or more jobItems, where each jobItem should be processed the same way for a job. E.g. if you have a calculatePayroll job, then each jobItem might be the employee you want to calculate the payroll for.
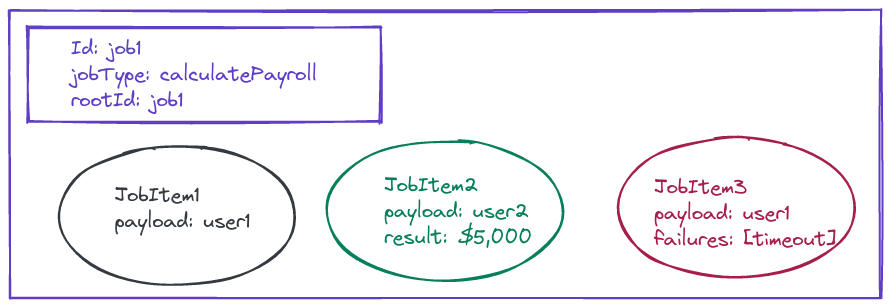
In this example, we see the calculatePayroll job has three jobItems. jobItem1 is still waiting for a worker to process it. JobItem2 was processed by a worker, which returned 5,000 as the result. JobItem3 was processed by a worker, but it returned a timeout error code
Streaming data
As mentioned in design considerations, async service requires that the root job, and all child jobs are created up-front. However, the data (jobItems) for any of these jobs (the root job, or especially child jobs) might not be known. Instead, async service supports the idea of streaming. Let’s take the following example. Consider the calculatePayroll example from above. However, once the payroll is calculated, now we want to send an electronic deposit to that user containing the desired amount.
Step 1: Create the job taxonomy
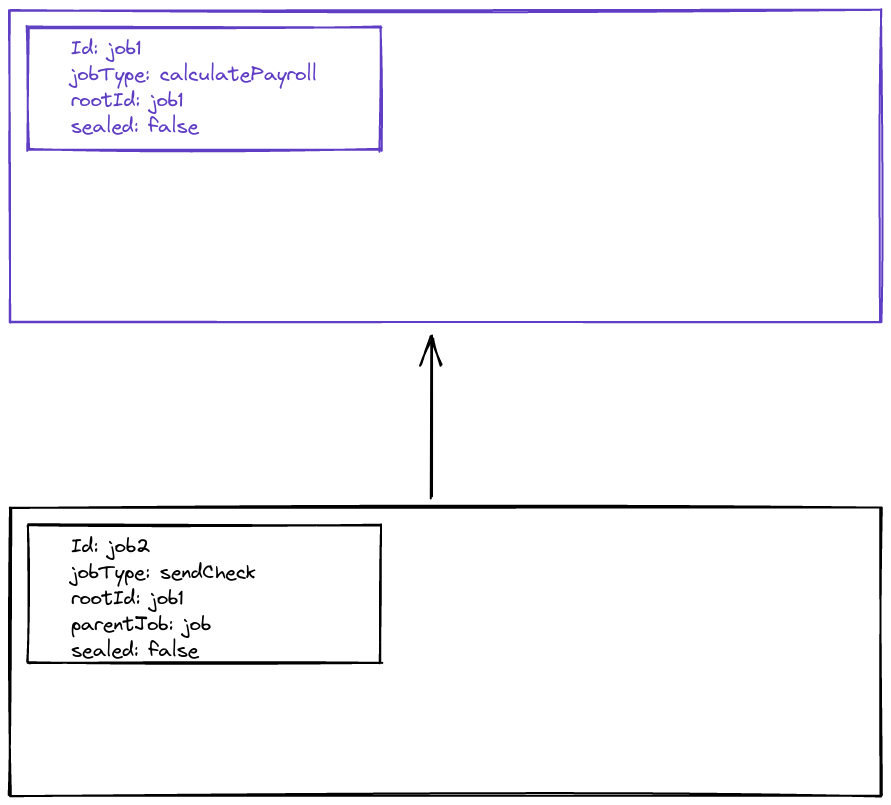
First we create the jobs, with the correct metadata for each job. The jobs are empty, and they don’t have any jobItems
Step 2: Add jobItems and seal the root job
Let’s say we already know the full set of users we want to calculate the payroll for. The next step is to load up the calculatePayroll job with jobItems. Afterwards, the job is sealed. Sealing a job sets a boolean on that individual job. It indicates that no more jobItems will be added to the job. This is important later, because we need to know if a job is finished. Even if all the jobItems within a job have finished, you still need to wait until no more items will stream into the job.
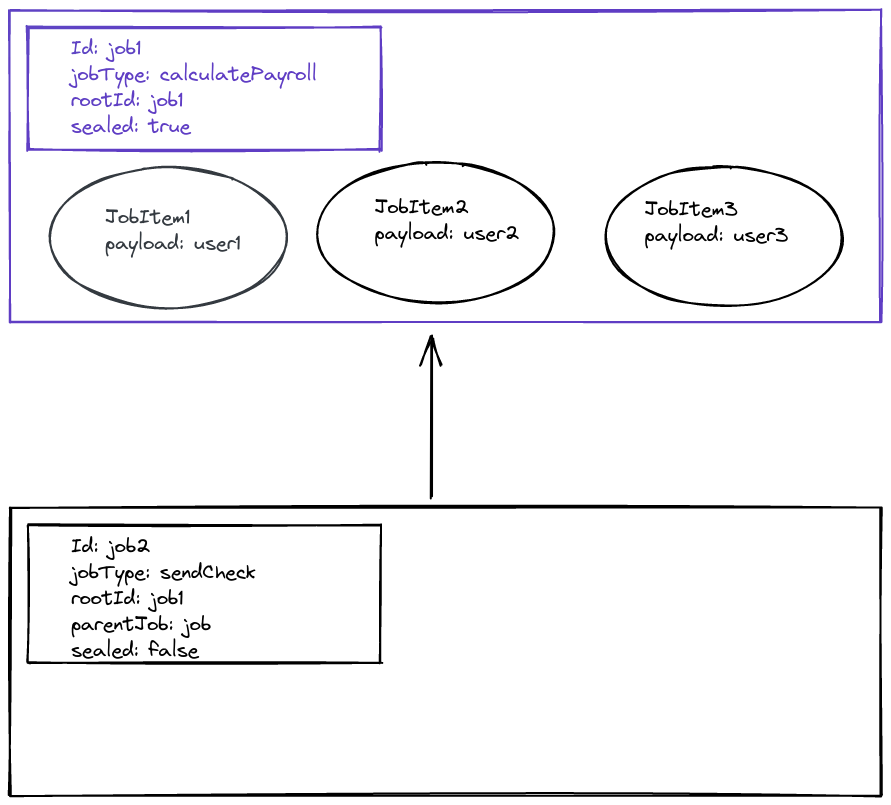
Step 3: Process the Job items and stream child items
Once a worker processes the job, it sends the result back to async service. In addition to updating the jobItem with the result, async service contains a local notification system where applets can react to different events. When a job item succeeds, it raises the JobItemSucceeds event. Jobs like sendCheck subscribe to these events and wait for the correct items to finish. When a calculatePayroll item succeeds, this applet registers a new jobItem. This item takes the result from the parent jobItem, and combines it to create the payload for the new jobItem. In this example, JobItem2 succeeded, and the applet inside async service created JobItem4 for the child job
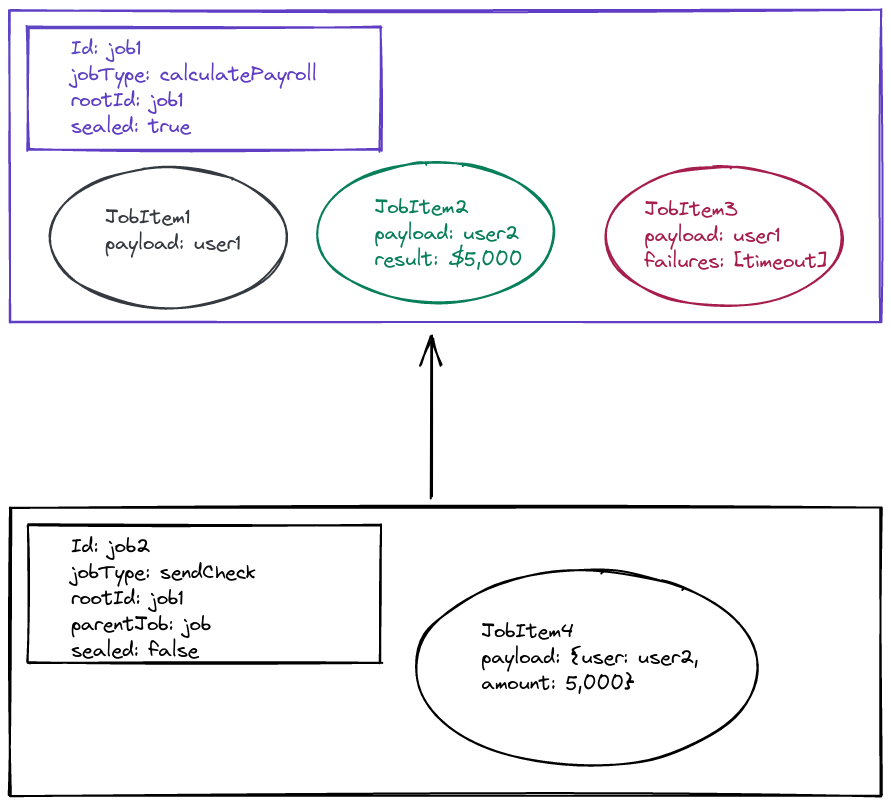
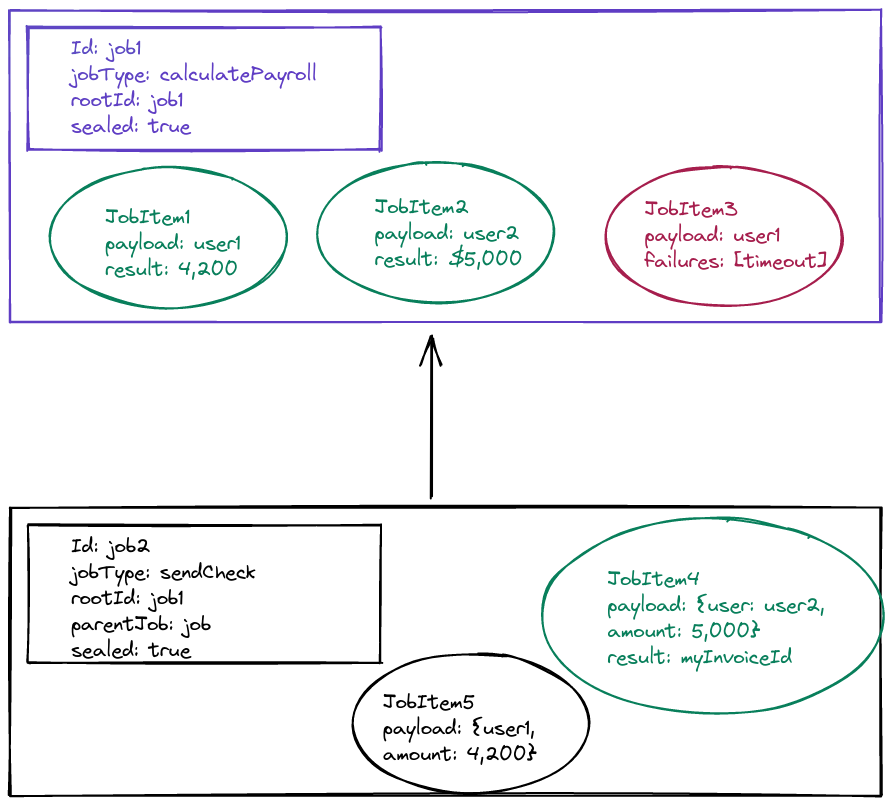
Step 4: Seal the child job once all root jobItems have completed
Once JobItem1 finishes processing (either successfully or not), async service can see that 1) The root job is sealed and 2) All jobItems are either succeeded or failed. Therefore, no more users will need to be sent checks, and we can seal the child job. In this fashion, the system can recurse down any level of jobs
Assigned JobItems
One important feature of async service is that only one worker can process a jobItem at a time. To enforce this, workers are required to ask async service permission to process a jobItem. Async service uses the atomic nature of inserting a row as the mechanism to enforce exclusive access. To do so, we need to split up a jobItem into 2 pieces, using a 1:1 relationship. Now, the JobItem contains the immutable pieces, specified during item creation. This includes things like the id, the payload, and other metadata. Then, data that is applicable to the worker is relegated to a new table, assigned_async_job_item. This table contains a reference to the jobItem, and it contains a UNIQUE constraint to prevent multiple rows from pointing to the same jobItem
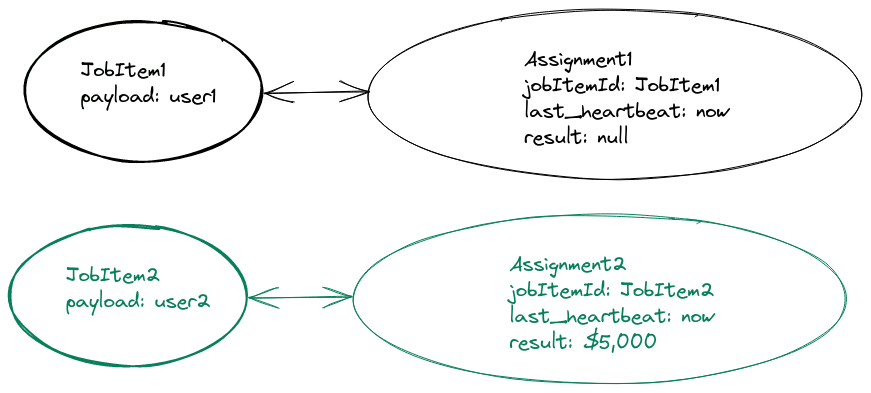
As further protection against accidental use, the assigned_async_job_item table contains its own UUID, called the assignment id. Workers are given the assignment id as a response to gaining exclusive access to the jobItem. When the worker wants to return success or failure, it must use the assignment id, not the jobItem id to indicate which item is affected.
In this picture, we see two jobs that have been assigned to workers. The top image is actively being processed by a worker. The worker sends heartbeats every minute, which is updated in the assigned table. The bottom image shows a jobItem that has completed successfully. When this happens, the result column of the assigned_async_job_item table is written to. Not shown, but by definition a jobItem which does not have a corresponding assigned_job_item row is not exclusively locked for a worker, and can be assigned at any time.
Additional features
Dedupe key
A common frontend pattern is to let the user click a button to start processing a task (such as taking a credit card payment). To prevent double-purchasing, frontends come with lots of tricks, but mostly they have the ubiquitous “Do not refresh your browser” message on them. Using async service, we can also help prevent such behaviors on the backend. Callers can specify an optional dedupe_key when creating either jobs or jobItems. This column is indexed, so multiple attempts to insert data with the same dedupe_key will fail.
Serialize key
Another common scenario is the requirement to process certain jobItems in-order, even across different jobs. Consider a scenario where you can issue disjoint commands. “Turn on the lights”. “Sound up to 100”, etc. In this scenario, the job types are unique (the service that handles lights is different than the service that handles sound). The serialize key is a flexible solution designed to solve these sets of challenges. The serialize key is similar to the dedupe key in that it is a unique column that prevents duplicates. However, the serialize key is part of the assigned_async_job_item, not the job item. This means you can create multiple jobItems that have the same key, but you cannot assign multiple jobItems matching the same serializeKey at the same time. Instead, job items containing the same serialize key are processed in insertion order. E.g. when workers go to process jobItems with serialize keys, only the worker trying to process the oldest jobItem will win and be allowed to process. Once that jobItem completes, then the next jobItem is available for processing.
Retry on failure
Workers can fail for many reasons. We need to detect this, and build in backoff/retry behavior. Detection is straightforward. The worker can tell us itself if processing failed. Otherwise, as mentioned earlier, workers are required to send a heartbeat API call every minute containing the assignment id. If the worker doesn’t check in within 3x this interval, it is assumed to have crashed, and the assignment is released. On the other side, when workers are not able to send two consecutive heartbeats, they automatically cancel to prevent multiple workers processing the same jobItem.
Determining what comes after a failure first depends on maxFailuresPerItem. This is a piece of metadata associated with a job which controls how many times a jobItem should be retried before giving up and marking everything as failed. jobItem failures are stored as an array of failures. The logic then is just to compare the length of failures vs maxFailuresPerItem to determine if retry should be allowed. The go code in async service determines what the appropriate backoff time is, and sets the retry_at metadata field on the failed job.
Finally, a cron job (yes a cron job) searches over the database regularly for jobs which 1) Haven’t exceeded the number of failures, and 2) which are beyond their retry_at time. These jobs are re-queued into rabbit and processing continues
FinalStage
Although jobs may contain many stages, typically the user is only interested in the final result. Async service allows jobs to fine-tune which results are sent back when getting results for the job tree. If finalStage is set to true, successful results are included, else they are ignored.
Completion notifications
In the true spirit of async jobs, callers don’t want to wait and poll for these jobs to complete. Instead, async service supports callbacks after completion. This metadata is stored in the root job, and checked after jobs complete
The SQL
Here it is in all its glory. Included are some examples for how to use the various stored procedures.
The table layout contains the three tables mentioned earlier: async_job, async_job_item, and assigned_async_job_item
CREATE TABLE async_job (
id text NOT NULL PRIMARY KEY,
insert_order serial,
job_type_id text NOT NULL,
root_id text NOT NULL,
parent_id text REFERENCES async_job ON DELETE CASCADE,
dedupe_key text,
UNIQUE (job_type_id, dedupe_key),
metadata jsonb NOT NULL,
created_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT async_job_root_id_fkey FOREIGN KEY (root_id) REFERENCES async_job (id) ON DELETE CASCADE
);
CREATE TABLE async_job_item (
id text NOT NULL PRIMARY KEY,
insert_order serial,
current_job_id text NOT NULL,
root_job_id text NOT NULL,
dedupe_key text,
UNIQUE (current_job_id, dedupe_key),
payload jsonb,
metadata jsonb NOT NULL,
failures jsonb NOT NULL DEFAULT '[]' ::jsonb,
created_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP,
updated_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT async_job_item_current_job_id_fkey FOREIGN KEY (current_job_id) REFERENCES async_job (id) ON DELETE CASCADE,
CONSTRAINT async_job_item_root_job_id_fkey FOREIGN KEY (root_job_id) REFERENCES async_job (id) ON DELETE CASCADE
);
CREATE TABLE assigned_async_job_item (
id text NOT NULL PRIMARY KEY,
job_item_id text NOT NULL UNIQUE,
worker_id text NOT NULL,
serialize_key text UNIQUE,
result jsonb,
created_at timestamp with time zone DEFAULT CURRENT_TIMESTAMP,
last_worker_heartbeat timestamp with time zone DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT assigned_async_job_item_job_item_id_fkey FOREIGN KEY (job_item_id) REFERENCES async_job_item (id) ON DELETE CASCADE
);State diagram
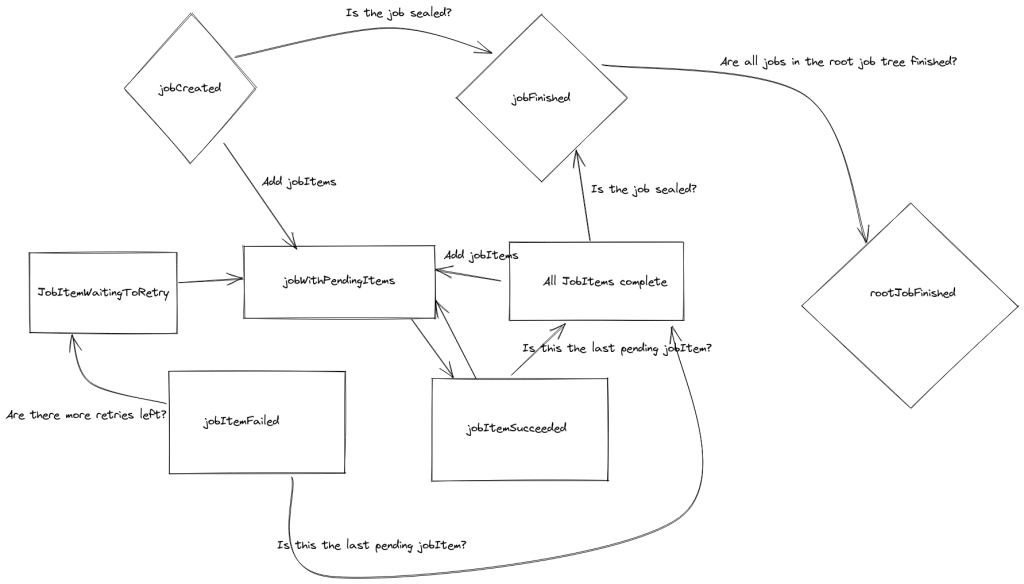
Generally speaking, here are the rules for how jobs and jobItems progress in the system
- A job is considered complete when it is sealed, and no jobItems associated with that job are pending
- The entire tree of jobs is considered complete when all jobs within that tree are complete per-the previous rule
- A jobItem can either be pending, succeeded or failed.
- JobItems are considered succeeded when the result column is non null (populated via a worker)
- JobItems are considered failed if the number of failures exceeds the maxFailuresPerItem metadata on the job
- A jobItem which has neither succeeded, nor failed is considered pending
- JobItems are considered locked to a worker when there exists a row in assigned_async_job_item with that jobItem, and the result is NULL
- A jobItem becomes unassigned if the worker fails. In this case, a failure is added to the jobItem and the assignment row is deleted
- A jobItem becomes unassigned if the worker succeeds. In this case, the result value is set to a non-null value
- A jobItem can be unassigned if the worker does not respond with a heartbeat frequently enough. This case is treated the same as a failure
- A jobItem is available to be assigned to a worker if:
- It is unassigned
- It has not succeeded
- retry_at is NULL OR
- the current time is after retry_at
- The serialize key is null
- OR the jobItem is the oldest jobItem that is still pending (oldest per insertion order)
HTTP Api
Currently, I’ve exposed the following REST routes to interact with async service
func (h *HttpApi) AddRoutes(router *mux.Router) error {
handler.AddSessionlessRoute(router, "/job", h.queryJobs).Methods(http.MethodGet)
handler.AddSessionlessRoute(router, "/job", h.createJob).Methods(http.MethodPost)
handler.AddSessionlessRoute(router, "/job/{id}/status", h.queryJobStatus).Methods(http.MethodGet)
handler.AddSessionlessRoute(router, "/job/{id}", h.deleteJob).Methods(http.MethodDelete)
handler.AddSessionlessRoute(router, "/job_item", h.queryJobItems).Methods(http.MethodGet)
handler.AddSessionlessRoute(router, "/job_item/{id}/worker/{workerId}", h.assignJobItemToWorker).Methods(http.MethodPost)
handler.AddSessionlessRoute(router, "/assignment/{id}/result", h.jobItemResult).Methods(http.MethodPost)
handler.AddSessionlessRoute(router, "/assignment/{id}/failure", h.jobItemFailure).Methods(http.MethodPost)
handler.AddSessionlessRoute(router, "/assignment/{id}/heartbeat", h.workerHeartbeat).Methods(http.MethodPost)
return nil
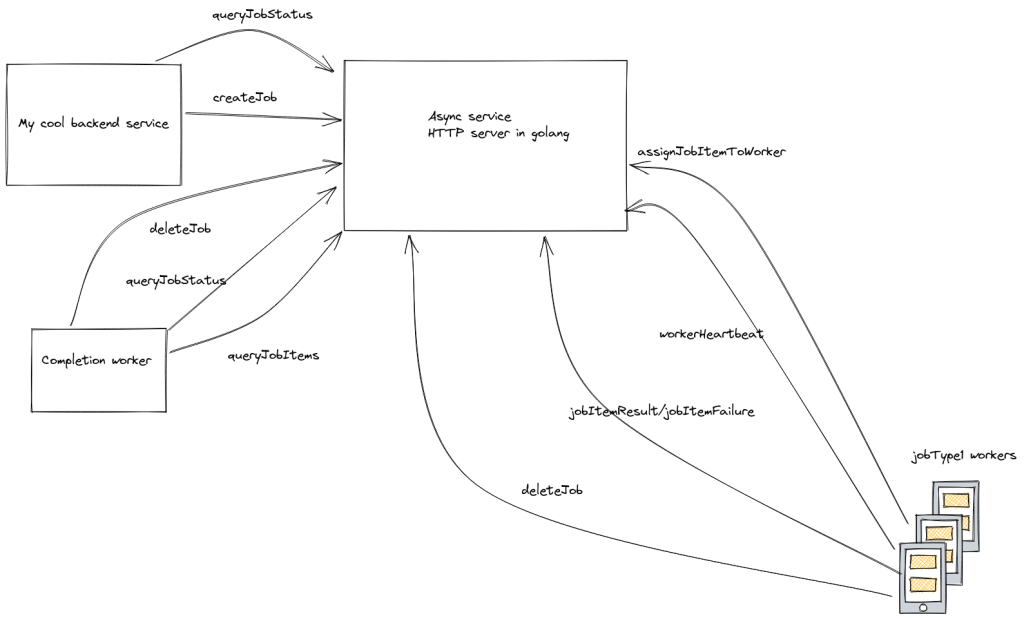
}Here’s the architecture diagram from the beginning of the blog post, but this time focused on the API calls different pieces make:
Cron jobs? In 2022?
Keeping two distributed systems in sync during failures, rollback, and backup restorations is difficult. For this reason, I didn’t want to make rabbitmq a required component for ensuring the correctness of async service. This is why rabbitmq is ephemeral. The data can be recreated at any time by scanning the database for various conditions. If messages are duplicated in rabbit, it doesn’t matter because the first one will win and the remaining ones will fail.
Instead, I chose to rely on cron jobs. Every minute, the system scans for jobs which have a missing heartbeat beyond the threshold. It scans for jobs which appear to be stuck and are not making progress.
I can get away with this design because there aren’t any realtime guarantees about async service. (It’s async!). You put work into the system, and at some distant point in the future, the jobs will be done. I suspect this system may evolve in the future but it’s a very pragmatic solution for right now.
Final results
By utilizing proven technologies in Postgres and Rabbitmq, I was able to achieve a robust implementation of async service using ~2,400 lines of code.
gocloc --not-match='.*_test.go' .
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Go 25 278 32 2370
YAML 24 65 68 845
SQL 2 86 19 840
Markdown 1 81 0 184
BASH 1 3 8 24
JSON 1 0 0 17
Plain Text 1 1 0 8
-------------------------------------------------------------------------------
TOTAL 55 514 127 4288
-------------------------------------------------------------------------------The test files added another 3,000 lines of code, making for a total of around 6k lines of code
gocloc .
-------------------------------------------------------------------------------
Language files blank comment code
-------------------------------------------------------------------------------
Go 35 487 50 5223
YAML 24 65 68 845
SQL 2 86 19 840
Markdown 1 81 0 184
BASH 1 3 8 24
JSON 1 0 0 17
Plain Text 1 1 0 8
-------------------------------------------------------------------------------
TOTAL 65 723 145 7141
-------------------------------------------------------------------------------So far I’m very pleased with the results. The system has a minimum number of technology dependencies. The primary logic lives in one place, and is backed by the very mature technology of postgres.
Scaling async service is straightforward, up to a point. The system is designed to spin up multiple instances of the HTTP server, to accommodate load. Cron jobs pick up any misplaced jobs during shutdown or rollover of these services.
RabbitMQ is a distributed system and should be able to scale (to the point where something else is the bottleneck).
Our current bottleneck in our backend isn’t async service at all. It’s the workers and related services using async service. If I try to load test the system, the services which are supposed to call async service start dying first.
Eventually though, the number of jobs will become an issue. I deliberately designed the sql to operate with disjoint data as much as possible. With one exception, you could shard the database by the root job id and everything would work perfectly. This only doesn’t work because of the serialize key. The point of the serialize key is to make jobItems in one job tree depend on other trees continuing.
If this dependency is removed, then scaling postgres horizontally becomes much easier. You just need to use a perfect hashing algorithm around the root job id to pick which database to talk to. But anyways, that’s then, this is now. We’re currently handling over 100k jobs per day using async service, just for one job type. This number will climb into the tens of millions by the end of the year, most likely. Very exciting!
Acknowledgements
I would like to thank the Dropbox team for posting their own architecture decisions. By the time I read the document, I had already converged on many similar ideas. I borrowed the heartbeat idea from that post.
Many thanks to Gary Soeller for listening to my ideas and offering feedback.
Innumerable thanks to David Lee for working through many devops hurdles to get this system deployed